AI Governance
How we held our AI governance manifesto to its own gate
AI governance only counts if it governs you first. We audited all 25 of our own plugins, gated the high-stakes ones, and signed the manifesto through the gate it describes.
At a Glance A governance manifesto only counts if it governs you first. We audited all 25 of our own plugins against five tests, added a named Release Owner gate to the 8 that move money or reach a customer, and built the rubber-stamp detector before we had a single reading. Then we signed the manifesto through that same gate. The honest part: the override-rate log starts empty.
Key Takeaways
- Generation got cheap and judgment didn't. McKinsey's 2025 Superagency report found 92% of companies plan to raise AI spending while only 1% of leaders call their company mature on it. That gap is a judgment problem, not a tooling one.
- We audited all 25 MoxyWolf plugins against five tests and gave the 8 high-stakes ones – money, e-signature, customer-reaching – a named Release Owner who signs before anything irreversible ships.
- We built a shared decision log and an override-rate report so "watch the override rate" is a number, not a slogan. It starts empty on purpose.
- The manifesto was signed through its own gate: the three questions asked, one named human on the line, the decision logged. The log's first two rows are that signature and one edit.
- None of this needed a better model. It needed structure you can run a whole portfolio through.
We wrote a manifesto about governing AI, and then we made our own software obey it before we published a word of it.
The way you make a governance policy real is boring and it's the whole game: you run it on yourself first. Anyone can publish principles. The test is whether your own tools pass them when nobody's grading on a curve. So before the manifesto went out, every plugin we ship got tiered by risk, the dangerous ones got a named human on the line, and the manifesto itself had to clear the gate it describes.
Here's what that actually took.
Why write a governance manifesto at all?
Because the constraint moved and most of the playbooks didn't notice. For most of the history of work, making the thing was the hard part. AI collapsed that cost toward zero, so the scarce resource isn't output anymore. It's the judgment that decides whether the output is any good.
The numbers say nobody's rebuilt around that yet. McKinsey's 2025 Superagency report found 92% of companies plan to increase AI spending over the next three years, and only 1% of leaders call their company mature on it. Enormous investment, almost no maturity. That gap isn't tooling. Everyone has the same tools. It's judgment.
And judgment fails in a specific, measured way. Anthropic's 2026 AI Fluency Index analyzed 9,830 conversations and found that when the model handed someone a polished deliverable, they were 3.7 points less likely to check the facts and 3.1 points less likely to question the reasoning. The cleaner the surface, the less anyone looks underneath. We named that the polish bias, and the companies most exposed to it are the fastest ones, because their whole advantage is producing more polished output faster than anyone else.
You don't beat a structural force with good intentions. You beat it with structure. That's what the manifesto is, and it's why a slogan wasn't enough.
What does it mean to run the manifesto on yourself?
It means grading your own software and fixing what fails.
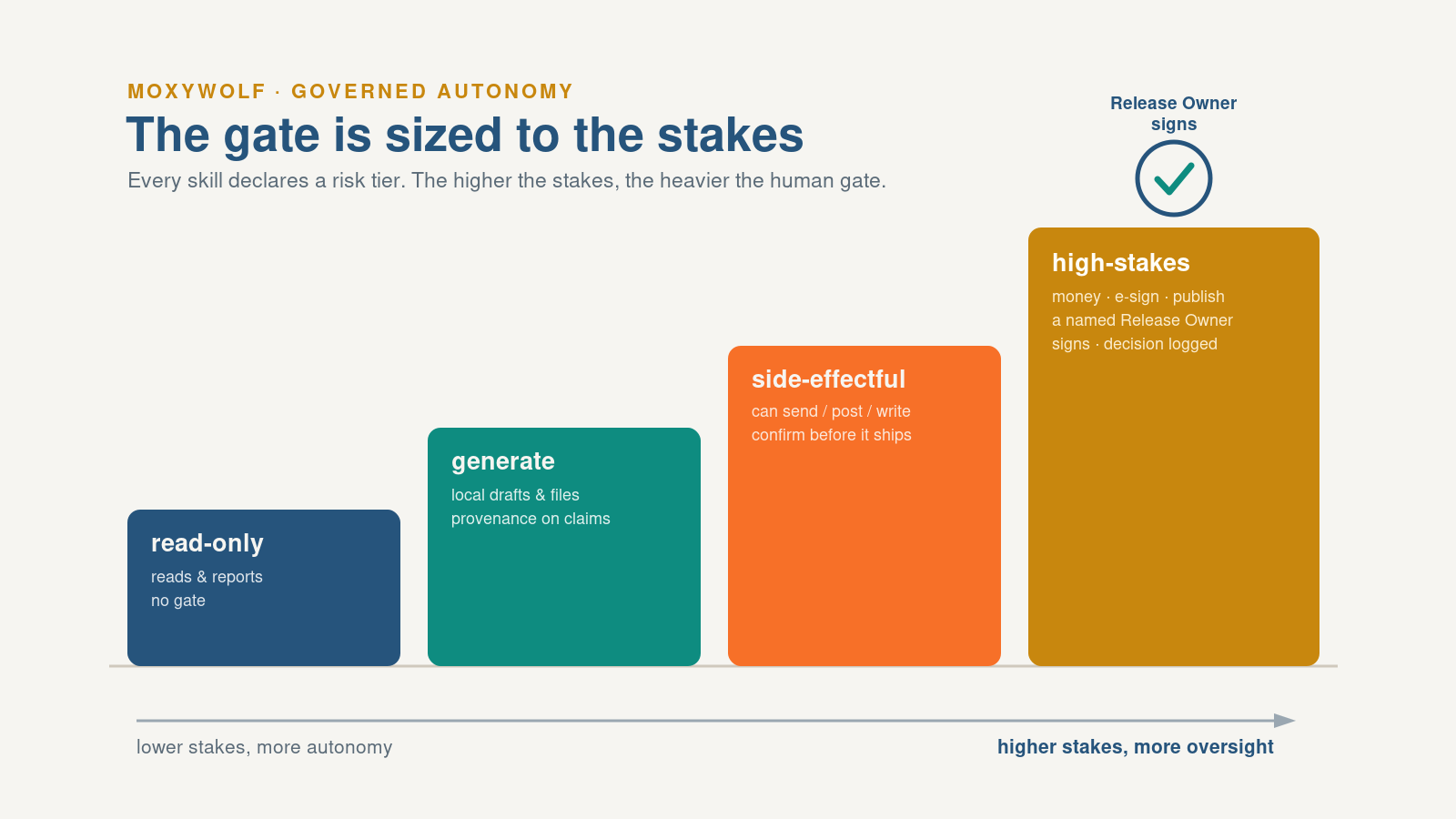
We took every plugin in our own toolset, 25 of them, and ran each against five tests drawn from the manifesto: a gate sized to the stakes, a named human on high-stakes output, provenance on factual claims, an auditable guard against rubber-stamping, and a human who owns the outcome no matter how much the machine did.
Three plugins already embodied it and became the reference pattern. Most of the rest were low-risk and needed only to declare their tier. A smaller set had real gaps. Tools that moved money or sent customer-facing messages behind a vague "ask the owner" instead of a named, recorded signature. A tool that broadcast to a shared channel with no checkpoint. Content tools that asserted claims without routing them through verification.
We closed those gaps rather than just cataloging them. Eight high-stakes skills – invoicing, payroll, refunds, e-signature, customer campaigns – now stop at a Release Owner gate. The skill presents the exact action and the recipient or amount, then waits. One named human signs with initials and a date, or it doesn't ship. Every plugin now carries a written risk tier in a governance file you can read. The audit was the point: a principle you can run a portfolio through is a different kind of object than a principle you can only nod at.
How do you keep a signature from becoming a rubber stamp?
You measure the signing.
A signature rots into a reflex the moment nobody's watching it. The manifesto's answer is to audit the oversight, not just the output: track how often the human actually overrides the machine, and how long they take to decide. A gate that's signed every time, instantly, isn't a sign of quality. It's a sign the gate is asleep.
So we built the instrument. Every high-stakes gate now writes one row to a shared, append-only decision log the moment a human signs or stops: who signed, what they decided, when, and against which action. A second tool rolls those rows into an override rate and a response time per skill, and flags two failure shapes prose can't catch: a gate that's signed every time as-is, and a gate cleared too fast for anyone to have read it.
Here's the honest edge, and it's the most on-brand sentence in this whole post: the log starts empty. We built the gauge designed to catch us before we had a single reading that might flatter us. That's deliberate. A company that ships its own rubber-stamp detector only after it has a clean record to show you is running the exact polish move the manifesto warns about.
What does it look like to sign a manifesto through its own gate?
Like answering three questions out loud and putting a name on the answer.
The manifesto says every high-stakes thing takes one named human asking three questions before it ships: is every claim grounded, does it sound like us, would I put my own name on it. Yes to all three, you sign. So that's how the manifesto got signed. Not auto-approved. Not "the team agrees." One named Release Owner, the three questions, a date.
Then the decision got logged to the same gate log every other high-stakes action uses. The log's first two rows are the manifesto signing itself off and one later edit, which means the very first thing our rubber-stamp detector ever recorded was the document that demanded it. The override rate on those two rows is 50%, which is meaningless at a sample of two and exactly the kind of number we refuse to dress up as a result.
That's the proof we care about. Not that AI wrote something. That the system caught what the polish would have hidden, with a human's name on the line.
What we got wrong, and logged
The second row in that log is an edit, and it's worth telling.
The first draft of the manifesto carried a first-person story about our founder selling his stake in a former company back for a dollar rather than watch the human get pulled out of the review. Strong story. Wrong voice. A teammate caught that if the team signs a document together, it can't speak in one person's "I." So we moved it to the third person, reframed the signature so the team declares and one named Release Owner still owns the call, and logged the change as an edit rather than quietly overwriting a signed document.
That's the small, unglamorous version of the whole idea. Someone caught a polished-but-wrong thing, a named human owned the fix, and the change left a trail. The framework, run on the framework.
FAQ
What is "human above the loop"?
It's the person who owns the outcome no matter how much of the work the machine did, as distinct from a human "in the loop" who reviews each step. Above the loop, you don't climb into every decision. You set which decisions the machine is allowed to make on its own, and you answer for the result. The accountability never gets automated, even when the work does.
Does every AI action need a human signature?
No, and a rule that says so eats itself. If judgment is the scarce resource, you can't spend it on every draft. You tier the gate to the stakes: low-risk reversible work runs with automated checks and sampled review, medium-risk gets rotating approval that can stop the line, and only high-risk or irreversible actions take one named signature before they ship.
How do you measure rubber-stamping?
You log every high-stakes decision and track two numbers: the override rate (how often the human changed or stopped the machine's proposal) and the response time. A very low override rate or a response time too short to have read the work are both warning signs that the gate is asleep. The point is to make the failure visible instead of invisible.
Where can I read the full manifesto?
The full MoxyWolf AI Governance Manifesto is being published to the OpenControls site. The academic treatment, "Governed Autonomy: Human Accountability Above the Loop in Agentic AI," lays out the same argument with full citations and is published under CC BY 4.0 with a DOI: 10.13140/RG.2.2.33030.74565.